
Java内存模型(JMM)
本文要讨论的是Java内存模型(JMM)。它的名字和JVM内存结构(见[[运行时内存详解]])很像,但是他们两个并不在一个层面,解决的问题也不一样。
- Java 内存模型定义了 Java 语言如何与内存进行交互,具体地说是 Java 语言运行时的变量,如何与我们的硬件内存进行交互的。
- 而 JVM 内存模型,指的是 JVM 内存是如何划分的。
JMM是并发编程的基础,只有对JMM有一定了解才能更好的理解Java的一些高级特性,如:
volatile等。因此本文将从以下几点进行讨论:
- 为什么要有Java内存模型?
- Java内存模型是什么?
- 并发编程的三个重要特性
1. 为什么要有Java内存模型?
Java是从JDK1.5之后才开始使用新的Java内存模型。一般来说,编程语言是可以直接使用操作系统的内存模型的。但是由于Java是一个跨平台的语言,要求JVM层面屏蔽掉不同操作系统和不同硬件的差异。因此自定义了一套Java内存模型。
Java虚拟机规范中定义的Java内存模型(Java Memory Model,JMM),用于屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并发效果。
2. Java内存模型是什么?
Java内存模型的主要目的是定义程序中各种变量的访问规则。即关注在虚拟机中把变量存储到内存和从内存中取出变量值的底层细节。
Java内存模型将内存抽象出了主内存和工作内存。主内存可以类比为硬件中的主内存,JMM规定所有的变量都存储在主内存中。每条线程都有一个自己的工作内存,工作内存中用于存储本线程使用的变量的主内存中的副本。不同线程之间的工作内存不可见,线程间的通信均通过主内存来完成。JMM的结构如下图所示:
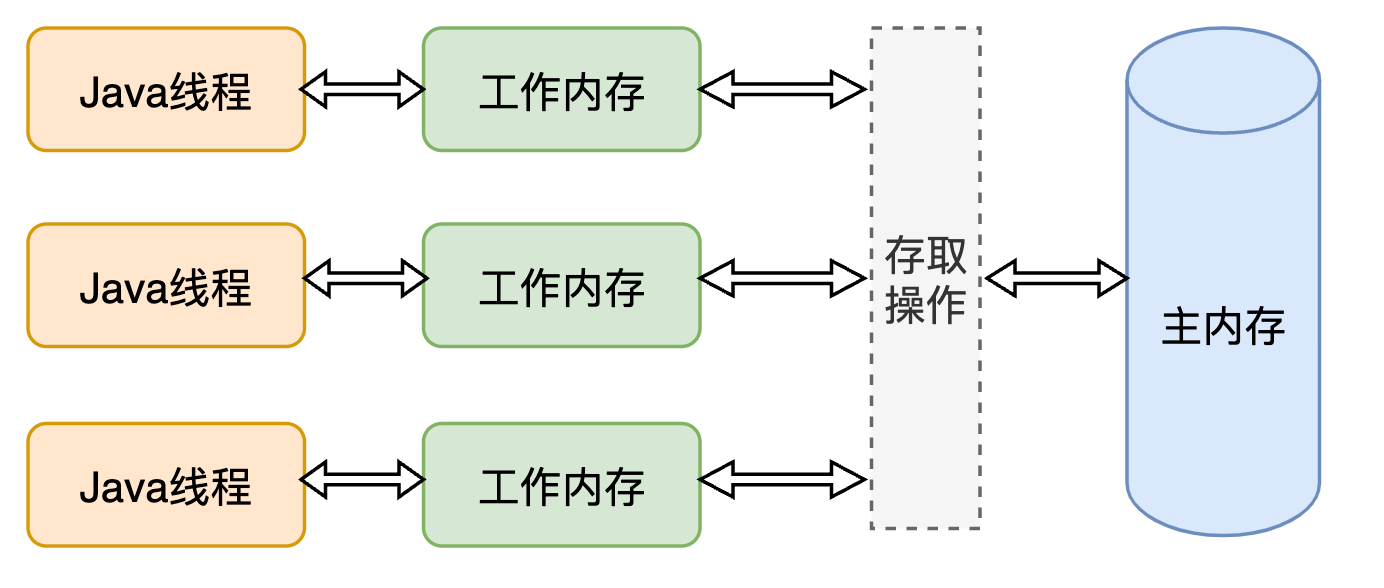
注意,这里所提到的主内存、工作内存与Java内存区域中的堆、栈、方法去等并不是一个层面的划分,其看待问题的层面不同。如果非要将其对应起来,那么主内存应该对应于JVM内存区域中的堆的对象实例数据部分。如果从更基础的层次上来看,主内存可以直接对应于硬件中的主内存(RAM),为了获得更好的运行效率,可能在JVM的实现上,尽可能地让工作内存优先存储于高速缓存中,因为程序运行时主要访问的是工作内存。
3. 并发编程的三个重要特性
并发编程的三个重要特性为:原子性、可见行、有序性。JMM也是围绕着这几个特性而建立的。接下来我们注意讨论。
3.1 原子性
Java内存模型定义了8种操作,每一种操作都是原子性的,分别是:lock(锁定)、unlock(解锁)、read(读取)、load(载入)、use(使用)、assign(赋值)、store(存储)、write(写入)。
我们可以基本上认为,基本数据类型的访问、读写、都是具备原子性的。唯一例外的就是long和double的非原子性协定,但是发生的几率非常非常小。
如果应用场景需要一个更大范围的原子保证,可以使用lock和unlock操作来满足这种需求。也就是使用synchronized。因此synchronized块之间也具备原子性。
3.2 可见性
可见性就是指当一个线程修改了共享变量的值时,其他线程能立即知道这个值已经修改。JMM通过变量修改后同步回主内存、读取前从主内存获取新变量这种依赖主内存的方式来实现线程间可见性的。其中,volatile关键字可以保证新值立即同步到主内存,且每次使用前立即从主内存中刷新。因此,volatile可以保证多线程操作时变量的可见性。
除了volatile之外,还有两个关键字可以实现其可见性。分别是synchronized和final。同步块实现可见性时由一条规则:“对一个变量执行unlock操作之前,必须先把此变量同步回主内存中”来实现的。被final修饰的变量在构造器中一旦初始化完成且没有把this传递出去,那么其他线程中就能看到final字段的值。
3.3 有序性
首先来看看重排序。
1 | public class Test { |
仔细阅读以上代码可知,如果不发生重排序的话,是不可能出现x == 0 && y == 0 的。
重排序由以下几种机制引起:
编译器优化:对于没有数据依赖关系的操作,编译器在编译的过程中会进行一定程度的重排。
大家仔细看看线程 1 中的代码,编译器是可以将 a = 1 和 x = b 换一下顺序的,因为它们之间没有数据依赖关系,同理,线程 2 也一样,那就不难得到 x == y == 0 这种结果了。
指令重排序:CPU 优化行为,也是会对不存在数据依赖关系的指令进行一定程度的重排。
这个和编译器优化差不多,就算编译器不发生重排,CPU 也可以对指令进行重排,这个就不用多说了。
内存系统重排序:内存系统没有重排序,但是由于有缓存的存在,使得程序整体上会表现出乱序的行为。
假设不发生编译器重排和指令重排,线程 1 修改了 a 的值,但是修改以后,a 的值可能还没有写回到主存中,那么线程 2 得到 a == 0 就是很自然的事了。同理,线程 2 对于 b 的赋值操作也可能没有及时刷新到主存中。
Java中提供了volatile来保证操作的有序性。volatile 的禁止重排序并不局限于两个 volatile 的属性操作不能重排序,而且是 volatile 属性操作和它周围的普通属性的操作也不能重排序。
比如DCL的单例模式中 instance = new Singleton() 中,如果 instance 是 volatile 的,那么对于 instance 的赋值操作(赋一个引用给 instance 变量)就不会和构造函数中的属性赋值发生重排序,能保证构造方法结束后,才将此对象引用赋值给 instance。DCL代码如下: ^8bb8ad
1 | public class Singleton { |
根据 volatile 的内存可见性和禁止重排序,那么我们不难得出一个推论:线程 a 如果写入一个 volatile 变量,此时线程 b 再读取这个变量,那么此时对于线程 a 可见的所有属性对于线程 b 都是可见的。
4. 总结
- Java 内存模型(JMM)定义了 Java 程序中的变量、线程如何和主存以及工作内存进行交互的规则。它主要涉及到多线程环境下的共享变量可见性、指令重排等问题,是理解并发编程中的关键概念。
- Java 内存模型(JMM)主要针对的是多线程环境下,如何在主内存与工作内存之间安全地执行操作。
- Java 运行时内存区域描述的是在 JVM 运行时,如何将内存划分为不同的区域,并且每个区域的功能和工作机制。主要包括方法区、堆、栈、本地方法栈、程序计数器。
- 指令重排是为了提高 CPU 性能,但是可能会导致一些问题,比如多线程环境下的内存可见性问题。