
Java的对象头结构
对象除了我们自定义的一些属性外,在HotSpot虚拟机中,对象在内存中还可以分为三个区域:对象头、
实例数据、对齐填充,这三个区域组成起来才是一个完整的对象。本文将对于对象头部分的结构进行讨论。
1. 对象的内存布局
对象在内存中可以分为三个区域,分别为对象头、实例数据、对齐填充。
- 对象头: 为本文的讨论重点,下文将会讨论;
- 实例数据: 存放类的属性数据信息,包括父类的属性信息;
- 对齐填充: 由于虚拟机要求 对象起始地址必须是8字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐。
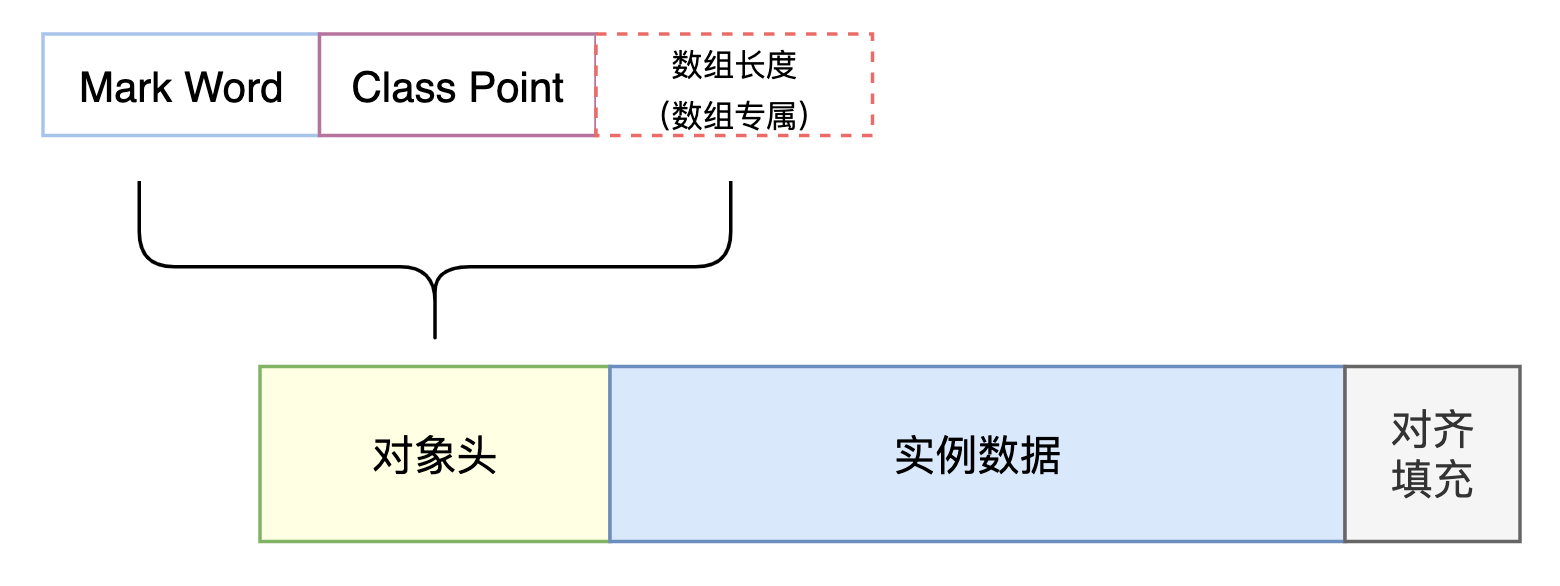
2. 对象头
对象头中存储了对象是很多java内部的信息,如hash码、对象所属的年代、对象锁、锁状态标志、偏向锁(线程)ID、偏向时间等,Java对象头一般占有2个机器码。
在32位虚拟机中,1个机器码等于4字节,也就是32bit,在64位虚拟机中,1个机器码是8个字节,也就是64bit
其中,如果对象是数组类型,则需要三个机器码。因为JVM虚拟机可以通过Java对象的元数据信息确定Java对象的大小,但是无法从数组的元数据来确认数组的大小,所以用一块区域用来记录数组长度。 HotSpot虚拟机的对象头包括两部分信息,第一部分为Mark Word,第二部分为class pointer,如果是数组对象,那么还有数组长度。每个部分占一个机器码。
接下来我们进行逐一解释。
2.1 Mark Word
Mark Word用于存储对象自身的运行时数据,如哈希码、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等。为了尽可能地压榨空间利用率,Mark Word被设计成一个非固定的数据结构,以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。
其不同状态下的结构如下:
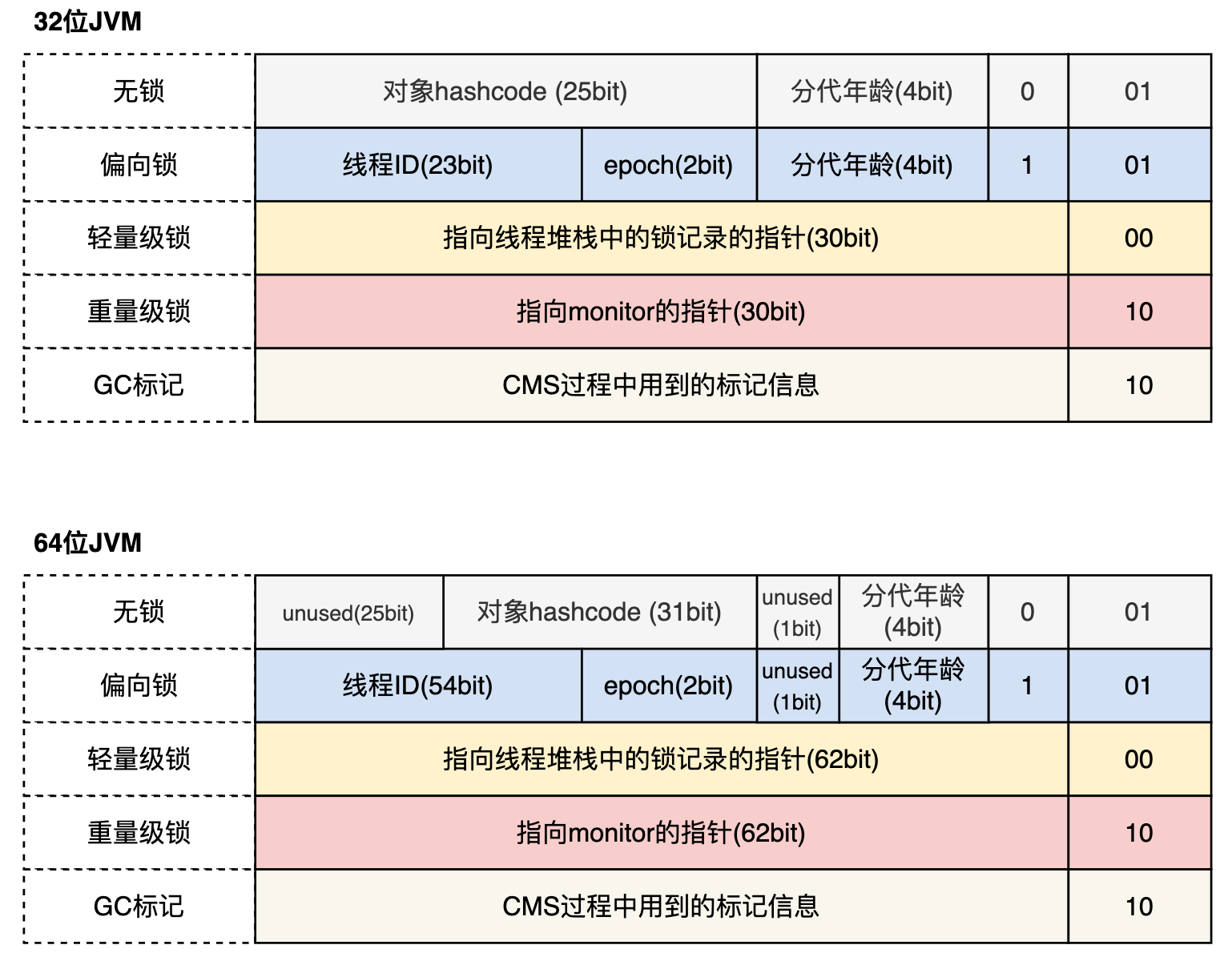
先看锁标志位和偏向锁标记位:
最低2位,锁标志位(lock)是表示对象的线程锁状态,其中,正常和偏向锁时都是01,轻量级锁用00表示,重量级锁用10表示,标记了GC的用11表示。由于正常和偏向锁时都是01,因此低3位 偏向锁标记位(biased_lock) 用0或1表示是否时偏向的。
在正常不加锁时:mark word 由lock、biased_lock、age、HashCode组成,age是GC的年龄,最大15(4位),每从Survivor区复制一次,年龄增加1。HashCode就是对象的哈希码,当对象处于加锁状态时,这个哈希码会移到monitor,(synchronized会在代码块前后插入monitor)。
在偏向锁时:mark word 由lock、biased_lock、age、epoch、thread组成。
epoch:偏向锁在CAS锁操作过程中,偏向性标识,表示对象更偏向哪个锁。thread:持有偏向锁的线程ID,如果该线程再次访问这个锁的代码块,可以直接访问。
在轻量级锁时:mark word 由lock、ptr_to_lock_record组成。ptr_to_lock_record:指向栈中锁记录的指针。
在重量级锁时:mark word 由lock、ptr_to_heavyweight_monitor组成。 ptr_to_heavyweight_monitor:指向对象监视器Monitor的指针。
2.2 Class Point
这一部分用于存储对象的类型指针,该指针指向它的类元数据,JVM通过这个指针确定对象是哪个类的实例。该指针的位长度为JVM的一个字大小,即32位的JVM为32位,64位的JVM为64位。
如果应用的对象过多,使用64位的指针将浪费大量内存,统计而言,64位的JVM将会比32位的JVM多耗费50%的内存。为了节约内存可以使用选项+UseCompressedOops开启指针压缩,其中,oop即ordinary object pointer普通对象指针。开启该选项后,下列指针将压缩至32位:
- 每个Class的属性指针(即静态变量)
- 每个对象的属性指针(即对象变量)
- 普通对象数组的每个元素指针
也不是所有的指针都会压缩,一些特殊类型的指针JVM不会优化,比如指向PermGen的Class对象指针(JDK8中指向元空间的Class对象指针)、本地变量、堆栈元素、入参、返回值和NULL指针等。
2.3 数组长度(Array Length)
如果对象是一个数组,那么对象头还需要有额外的空间用于存储数组的长度,占一个字大小。64位JVM如果开启+UseCompressedOops选项,该区域长度也将由64位压缩至32位。